Versatile C++ game scraper: Skyscraper
-
@analoghero Thanks, I could try a little hacking (modifying the source) here to see if i can force the localdb in the mounted hd. It's out of my coding skills, but having a windows port could be a lot lot easier, i tried Cygwin, but as muldjord told me, this is not going to work so easily.
-
@bleuge The ability to define the path for localdb is an option i also would like to see. Great for us that use usb sticks and hdd's.
-
@bleuge @Rion Not sure how you are running Skyscraper but there is
-dswitch which may be of interest. If you run the commandSkyscraper --help, you can see all the available options.Here is the relevant output for the
-dswitch:-d <folder> Set local resource database folder. (default is '[homedir]/.skyscraper/dbs/[platform]') -
@dudleydes I should have checked before i write. Looks like it isnt hardcoded then.
-
@dudleydes That you for pointing that out. 😀
-
Edit - Reference @bleuge request to change the localdb location due to limited space on the SD...as well as my diatribe below:
As suggested, I've "solved" this by mounting a network store in the .skyscraper/dbs folder (via fstab mod, although recommended is through autostart.sh)
This gives the best solution for me, as it caches the downloaded media files in the NAS storage for when I'm home/on my LAN. That's where I would be doing any updates to the scraping anyway. When I take the Pi with me, I don't need the cached files, just those I'm actually using through the final "Skyscraper localdb" command.
I believe the other comments and readme docs mean you could put the localdb on either a separate USB attached drive, or potentially a network share.
However...is it acceptable to just delete the localdb files once you've updated? Assuming you understand the risk that they (obviously) aren't available anymore to reference if you decide to do a full update.
More specifically, when you run updates later for added ROMs, will it delete or corrupt the old information when you overwrite the XML if it can't find the media in the localdb?
In my scenario, with updating initially from import, I could have THREE copies of the same file on the SD. And if we're talking video, that's a lot of space.
1st copy: You import the video files to .skyscraper\import\videos
2nd copy: Run "Skyscraper -p [platform] -s import --videos" and the videos are all copied (and renamed) to skyscraper\dbs[platform]\videos\import folder.
3rd copy: Run "Skyscraper -p [platform] -s localdb --videos" and the videos are all copied again (and renamed back to original) to the roms[platform]\media\videos folder.I assume I can delete the 1st copy once I'm done, but at minimum I still have two copies of the video.
Wouldn't a hardlink between the database and the actual video in the rom folder be better at saving space?
Regardless, as above, can I delete the localdb media files once they've been scanned and copied to the ROM folder without risk of when I update it says "oops, no file, better update the XML file to say it doesn't exist?"Thanks - I tried to make this as clear as possible.
-
@timekills Sure, you can delete the dbs folder. I wouldnt recommend it though, as skyscraper would need to download everything again if you ever want to rescrape.
Maybe youre better off zipping it and storing it elsewhere, so you can reuse it later.Btw: Whats the best way to get video files for your roms? No luck with skyscraper atm.
-
@analoghero I figured as much, but thank you for confirming. It just seems to me there is a better way to store the database if you don't have a need to keep duplicates. Even a choice with a warning to remove once they've been transferred to the ROM folder (or whatever location). I understand anything short of keeping a copy, either local or on a remote localdb location means redownloading.
Regarding video download location, I don't have a great suggestion ATM because I'm fortunate enough to have downloaded all the video snaps over the years. My go-to is always EmuMovies, as I've had an account with them for years. All the way back to when they actually mailed me a full seven DVD set of snaps for everything they had at that time.
-
https://www.reddit.com/r/RetroPie/comments/828a0p/best_way_to_scrape_games_in_2018
Skyscraper wins ;-)
Also thanks for the -d option, I checked the help, but don't know why i missed it.
-
@bleuge This makes me happy. :) Thanks to all of you for your support.
I've just arrived home from a trip to Africa. I'll probably take a couple days to rejoin the internet and then I'll get right back on Skyscraper duties. :)
-
@muldjord Welcome back :)
Have to report good things about using skyscraper. Bought a new (bigger) microsd and thought maybe its time to do video snaps. Backed up my (known good) dbs folders, but deleted them later (because of owner issues, another story). So rescraped everything again (think ive done it 10 times now).
Results are amazing. :)
Have some ideas to improve skyscraper, but just take your time now to sort your things first.
-
@analoghero Happy to hear that! I am currently investigating some stuff with Dom from the Amiberry team for optimizing Amiga scraping and I also need to implement the Mobygames(.com) scraping module. But just post your ideas here and I'll check them out.
-
Has anyone tried scraping SNES recently and successfully had the ratings included?
Across the multiple sites that Skyscraper uses, only thegamesdb seems to get ratings pulled by Skyscraper, and it's not very compelete.However, if I use another scraper (UXS, SSelph, etc.), they will get the ratings from other sites that Skyscraper also uses, to a much higher completion rate (nearing 100% from screenscraper...)
Of course, the problem is none of the different scrapers can agree on how to format the gamelist.xml file, much less where to store the media, so each one overwrites the other.If there were a way to import the data for ALL the games at once, it would be fine. But breaking apart a gameslist.xml file into each one of 1000+ roms and naming each file...not really viable.
Bottom line: any good way to either
- Get the ratings when scraping (specifically SNES, can't speak to other games yet.)
or - Merge the gamelist.xml file from another scraper without having to create 1000+ individually named txt files?
(Note: I could not find in the priorities.xml which of the choices prioritizes which site's ratings are used or how to format just priorities when importing your own data files. I assume it's part of "description", but I don't need or want to overwrite the WHOLE description - just the ratings.)
- Get the ratings when scraping (specifically SNES, can't speak to other games yet.)
-
@timekills You can just add the <order type="rating"> node yourself in the priorities.xml file. I had no idea screeenscraper has ratings, so I haven't implemented it. I will look into it straight away and see if I can find it. If I can, it will be included in 2.3.6 which will be released shortly (probably today or tomorrow).
EDIT: Just had a look at the screenscraper xml and I can't find a rating / score anywhere. If you have any information on this, please let me know. Do you mean age rating?
-
@muldjord While i had to rescrape everything again (Snes, nes, mastersystem, megadrive/genesis, arcade, amiga, neogeo, atari7800, c64) i had a few ideas.
I ran Skyscraper without arguments first, for each system. Then i scraped again with
-s screenscraper --videosfor the console systems.So what would be nice:
- If you could run skyscraper to scrape specific data for example screenshots.
- If you could check what data is missing.
- A different artwork.xml for arcade. I know i should do this by myself, but im not good at it :)
I hope you dont get me wrong, as skyscraper works good as it is and i know you do this in your spare time. Consider this as a input from an user, not a demand :)
-
@muldjord said in Versatile C++ game scraper: Skyscraper:
@timekills You can just add the <order type="rating"> node yourself in the priorities.xml file. I had no idea screeenscraper has ratings, so I haven't implemented it. I will look into it straight away and see if I can find it. If I can, it will be included in 2.3.6 which will be released shortly (probably today or tomorrow).
EDIT: Just had a look at the screenscraper xml and I can't find a rating / score anywhere. If you have any information on this, please let me know. Do you mean age rating?
I don't know what I was thinking...you are correct, it definitely was not screenscraper.
I'll also note that after re-prioritizing the sources and running again from thegamesdb, I did get an equivalent rating listing. Mea culpa, and I apologize for the red herring. (aside - allowing users to enter their username/password might help with the thread allowance for sites such as screenscraper, not to mention get you some good karma with them for the "free" advertising.)The request part remains as you answered however, and I appreciate that. I'm still a little unclear from the various instructions on importing prior data if I have to create a separate list for each individual game, or if it will scan for the <game> or <name> and add the correct <rating> (or whatever order type is associated) from large, contiguous file including all the games in certain system.
@AnalogHero request above, specifically the run for specific named data such as you can for videos, would assist in this. I realize whenever you run a scrape with --pretend it should update any missing data information, which then you can lock in with the localdb. Would scraping for just one data type speed this up?
What I think would be even better than telling it what to change/scan for, would be telling it what not to change/scan for. I.E. I already have a list of screenshot files that are compilations I want to keep. I've been doing this by importing and setting <source>import</source> as the top in the <screenshot> group and running a --pretend update just to update the localdb files then a -s localdb set. It seems to work, but adding the ability to deselect a data point would make this a bit less complicated.
Finally, I may have missed it but do you have a Patreon or some other donation site? Although many of us (cough me cough) sound like typical complaining about a free service whiners, I recognize how much capability you've provided with this fantastic scraper, and would like to donate.
-
@timekills @AnalogHero, Concerning scraping just one type of resource: I have a bit too much on the plate as it is right now, so it won't be possible anytime soon. I do however think it could be done, so I'll make note of it. Thanks for the suggestion.
@timekills, Concerning user credentials for screenscraper it is actually already halfway implemented. It's something I want to look into soon. Especially since I just updated it to the V2 api from screenscraper.
@timekills, I've never actually had a Patreon but I just created one. If anyone wishes to support my work, feel free to do so. BUT, keep in mind that doing so is in no way a requirement. I mainly do this for my own amusement and self-education. :)
-
@muldjord Few (more) concerns/notes:
-
When (attempting to) update from 2.3.5 to 2.3.6 by executing "./update_skyscraper.sh" it returns that you are already at the latest version. The var $LATEST returns 2.3.5 so it doesn't execute as it already believes it is update to date.
-
You still have to manually add --updatedb for the textual updates to take. When I ran it with just -s import it updated the media but not the text. When I added the --updatedb with the same files it also included the text updates.
-
And I ran a UXS scrape of Atari 2600 and got ratings for about half of them. The amount isn't really relevant; what is relevant is that UXS only scrapes from ScreenScraper and it is giving ratings.
I'll be buggered if I can figure out where they're stored on the site or how to access them short of another scraping application.Found it (see below screenshot.)
(Just in case, I deleted all data for the 2600 ROMs just to ensure there was no historic data changing the test before I ran the UXS scrape of ScreenScraper.)
Example:
<game id="14008" source="ScreenScraper">
<path>/home/pi/RetroPie/roms/atari2600/Activision Decathlon, The (USA).zip</path>
<name>Activision Decathlon, The (USA)</name>
<desc>removed to shorten</desc>
<image>/home/pi/RetroPie/roms/atari2600/media/screenshots/Activision Decathlon, The (USA)-image.png</image>
<marquee/>
<video/>
<thumbnail/>
<rating>0.8</rating>
<releasedate>19840101T000000</releasedate>
<developer>Activision</developer>
<publisher>Activision</publisher>
<genre>Sports</genre>
<players>1-4</players>
</game>
Breakout (USA) at screenscraper.fr rating:
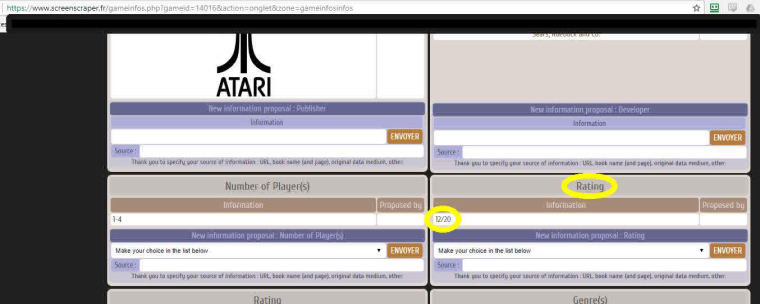
-
-
-
2.3.6 is not out yet, so you have the latest version (you can always check it here: https://github.com/muldjord/skyscraper/releases) :) I always post about new versions here aswell. I wanted to release it yesterday but I've postponed it a bit because I have some stuff I'd like to include. But maybe I'll just release it and include the rest later.
-
I just checked this, and it already adds '--updatedb' automatically whenever you use '-s import'.
-
Looks interesting with the rating of atarigames. I'll try running some through and see if I can find an entry that has it. Then it'll be piece of cake to include it. If I can find it, I will include it in 2.3.6. :)
EDIT: I found the rating! It's called "note" which I always assumed was some kind of... well, note. I had no idea that translated to "rating" in english. Anyways, it's now implemented and will be in 2.3.6.
-
-
Skyscraper version 2.3.6 released: https://github.com/muldjord/skyscraper
- Completely rewrote the openretro parser to make use of the 'edit' page instead
- Added '*.lha' suffix to amiga platform
- Changed default scraping module for all platforms to 'localdb'
- Added 'wheel' support to 'openretro' scraping module
- Rewrote thread queue so entries are always taken alphabetically
- Now forces 4 threads for 'screenscraper' scraping module to accomodate their limits
- Updated screenscraper API to use v2
- Added 'rating' to screenscraper scraping module
This release is a "bits and pieces" release. Nothing ground-breaking, but still important changes. The most important one being that each thread now works from a global file queue instead of splitting all files into groups and handing a group to each thread. The old way meant that some threads completed their work faster than others, resulting in a potential slowdown at the end of a scraping run because some threads had finished before others.
To update check the documentation on the github page.
Happy scraping! :)
Contributions to the project are always appreciated, so if you would like to support us with a donation you can do so here.
Hosting provided by Mythic-Beasts. See the Hosting Information page for more information.