Skyscraper now officially part of RetroPie, please test
-
@mitu Thanks for getting back to me, that works over ssh, but not with my keyboard plugged into the raspberry pi, so I'll have to figure out what that's configured as, but thanks!
-
@iainjh Use the command line parameters to purge/vacuum - https://github.com/muldjord/skyscraper/blob/master/docs/CLIHELP.md.
-
-
@mitu awesome that works fine now. Thank you very much for your help.
-
@2fst4u Alright then - thank you again for reporting the bug.
If you find any bugs/problems/questions with the menu/scriptmodule, please use this topic, I'm always notified when someone posts. -
Lovely job, working beautifully now. thank you!
-
Hi, just a question out of curiosity:
What happens when you scrape with a second source after having already scraped everything once? Does Skyscraper only scrape for information/files that were missing, or does it re-scrape everything? I see in the docs it mentions a couple of times about using a second source to fill in gaps, but I can't find anywhere what it actually does when you use a second source.
I also understand there is a way to set priorities for scraping sources. If the answer to the above question is "it only scrapes missing information", then what does this priority do? Does it overwrite data from a lower priority source and leave higher priority data untouched?
-
@2fst4u said in Skyscraper now officially part of RetroPie, please test:
What happens when you scrape with a second source after having already scraped everything once? Does Skyscraper only scrape for information/files that were missing, or does it re-scrape everything? I see in the docs it mentions a couple of times about using a second source to fill in gaps, but I can't find anywhere what it actually does when you use a second source.
Please read this: https://github.com/muldjord/skyscraper/blob/master/docs/USECASE.md
If you gather resources from the same source twice and it didn't finish all of your roms the first time around, it will load all of the ones you already gathered for with that source from the cache until it reaches one it doesn't have cached data for. Then it will start fetching it from the source directly. So in a way, it "skips" the ones you already gathered for using said source. You can tell from the
From cache: YES/NOin the output. But it's much easier to use the--startatand--endatoptions so you don't have to wait for it to load each entry from cache again.Concerning gathering using a /second/ source, it will regather for /every/ file. Skyscraper can cache each resource once per source. So when gathering from a second source it will cache all data once more.
The clever part of this is that you can at /any/ time change anything in your source priorities or your artwork config, and even decide to change your frontend to attractmode. And all you have to do is run a game list generation run again, and you will have a new game list for that frontend using the new configs you've applied. No need to gather new data at all because you already have all of it cached.
I also understand there is a way to set priorities for scraping sources. If the answer to the above question is "it only scrapes missing information", then what does this priority do? Does it overwrite data from a lower priority source and leave higher priority data untouched?
There is no overwriting going on anywhere. The priorities are used /only/ when generating the game lists. If you prefer the screenshots from a particular source, you'd prioritize that higher than other sources for the screenshots and so on. You can do this will all resource types for each platform.
-
@muldjord thanks, good to know. One more question about priorities then, what happens to your gamelist.xml if you don't set priorities but you have data from multiple sources scraped?
-
@2fst4u said in Skyscraper now officially part of RetroPie, please test:
@muldjord thanks, good to know. One more question about priorities then, what happens to your gamelist.xml if you don't set priorities but you have data from multiple sources scraped?
Then it uses the default priorities.xml. If the source isn't mentioned it uses timestamps, so the latest gathered resource for any type has priority over the others.
-
@muldjord oh cool that's awesome.
-
the windows version used with cmder look perfect
https://cmder.net/can u update the windows version to last one?
or can u write a guide for to compile it for windows. i dont ask everytime for updated version~~edit: forgot all , i success to compile it with qt 5.
Starting scraping run on 2825 files using 1 threads.
Sit back, relax and let me do the work! :)ScreenScraper APIv2 returned invalid XML
First 256 characters of answer was:#1/2825 (T1) Pass 1 ---- Game '005' not found :( ----
0/1/1
Elapsed time : 00:00:04
Est. time left : 03:11:25User wants to quit, trying to exit nicely. This can take a few seconds depending on how many threads you have running...
Request timed out, aborting request...arcadedb work great, screenscraper got error.
is this a windows problem or what?
version 3.1.5
very very thanks for your work -
@frezeen I don't know but I recon it's because of screenscraper limits. The network requests work exactly the same under Windows, so I don't think that's the problem. Might also be a firewall problem, might be that you compiled it wrong, I have no idea. You're on your own here basically. Good luck! :)
-
@muldjord got same error with 3.1.2 from github, its not a compile problem. arcadedb work good and its very fast vs rpi. ill try to found the problem.. anyways i know , no support for windows but thank for the reply , i appreciate it. ill update if i found the problem ;).
skyscraper has a debug function? i try with verbose 3 but cant log what happened when got error@all asking for someone in forum has a 3.1.2 windows from github working with screenscraper... this help me to understand if its my problem or not.
-
I think I've found another issue. I have set my cache folder to be on my USB drive. Here's what works properly:
- Scraping caches the data in the correct place on USB.
- Compiling the gamelist correctly uses the cache for all the data.
- Scraping again will use the cache to skip over things that don't need to be downloaded.
But what doesn't work is:
- Vacuum
- Purge
It seems the things that are working are using the correct cache location but the vacuum and purge aren't looking at my cache folder set in config.ini, it looks like it's using the default location? Whenever I go into the cache menu it says the size is "56K" which looks to be a baseline default, and it doesn't show all my systems that I want to purge, it only shows the ones that I previously scraped on my SD card.
The cache purge works fine in the default location, but now that I want it in a different place I'm still not able to purge.
-
@2fst4u The cache size is calculated from the default location, the script doesn't support custom cache locations.
However, the purge and vacuum actions are usingSkyscraperand they don't look there - what happens if you run the purge and vacuum from the CLI ? -
@mitu, @2fst4u If
cacheFolderis set in config.ini it will cache data there and purge and vacuum data from there aswell unless a separate-dis set on commandline by the script. There is no difference in the cache location between those operations, they all adhere tocacheFolderin config.ini.EDIT: Just moved my own cache to a non-default location, changed the
cacheFolderto point there and ran bothvacuumandpurge:all. It works as expected. -
I'm not able to run the purge command from the script because it only shows one system - GBC, when I have many systems on the USB drive that have been scraped.
Edit: here is my list when I go to "gather resources" or "generate gamelist":
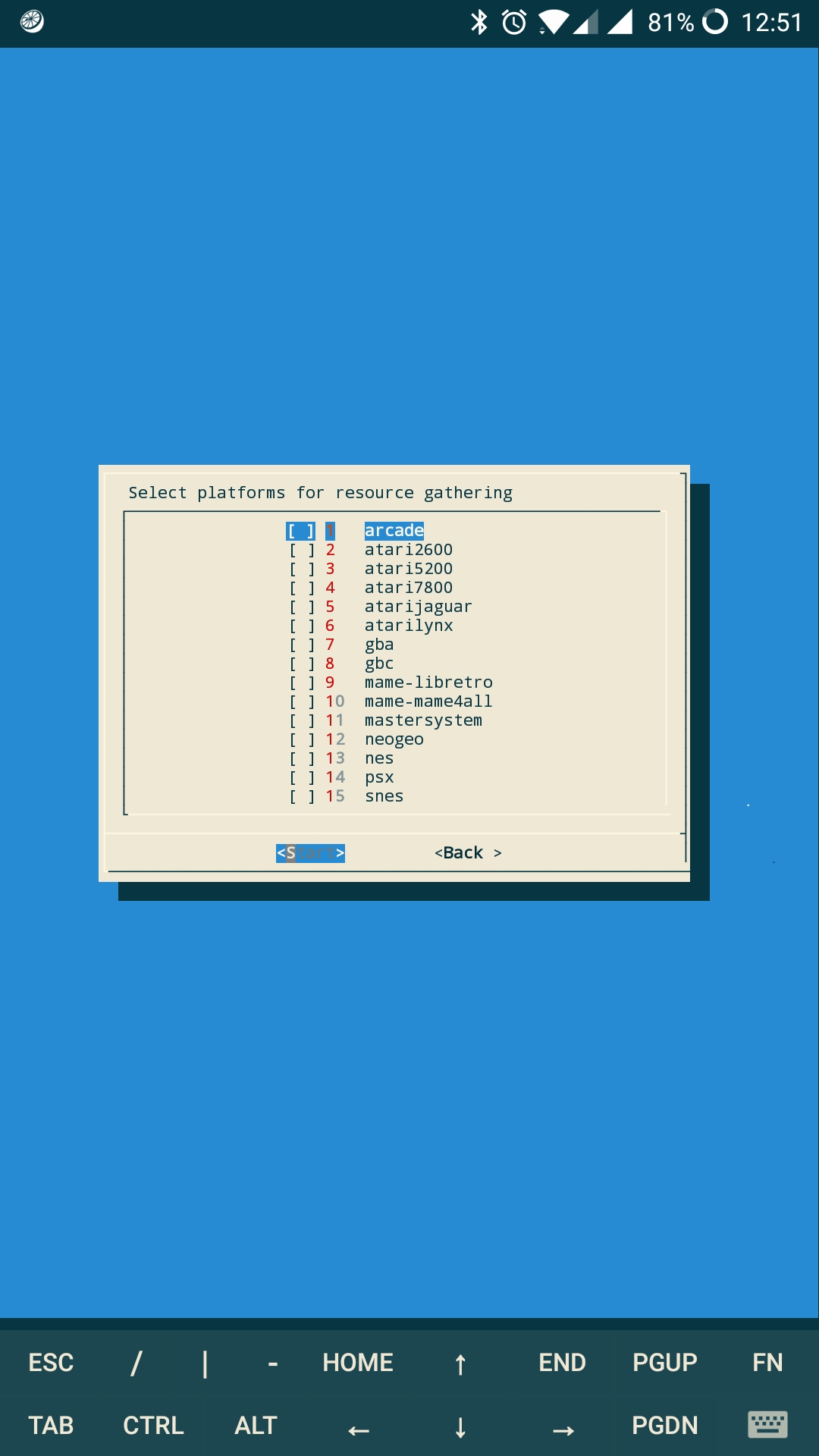
But here is my list when I try to "vacuum" or "purge":
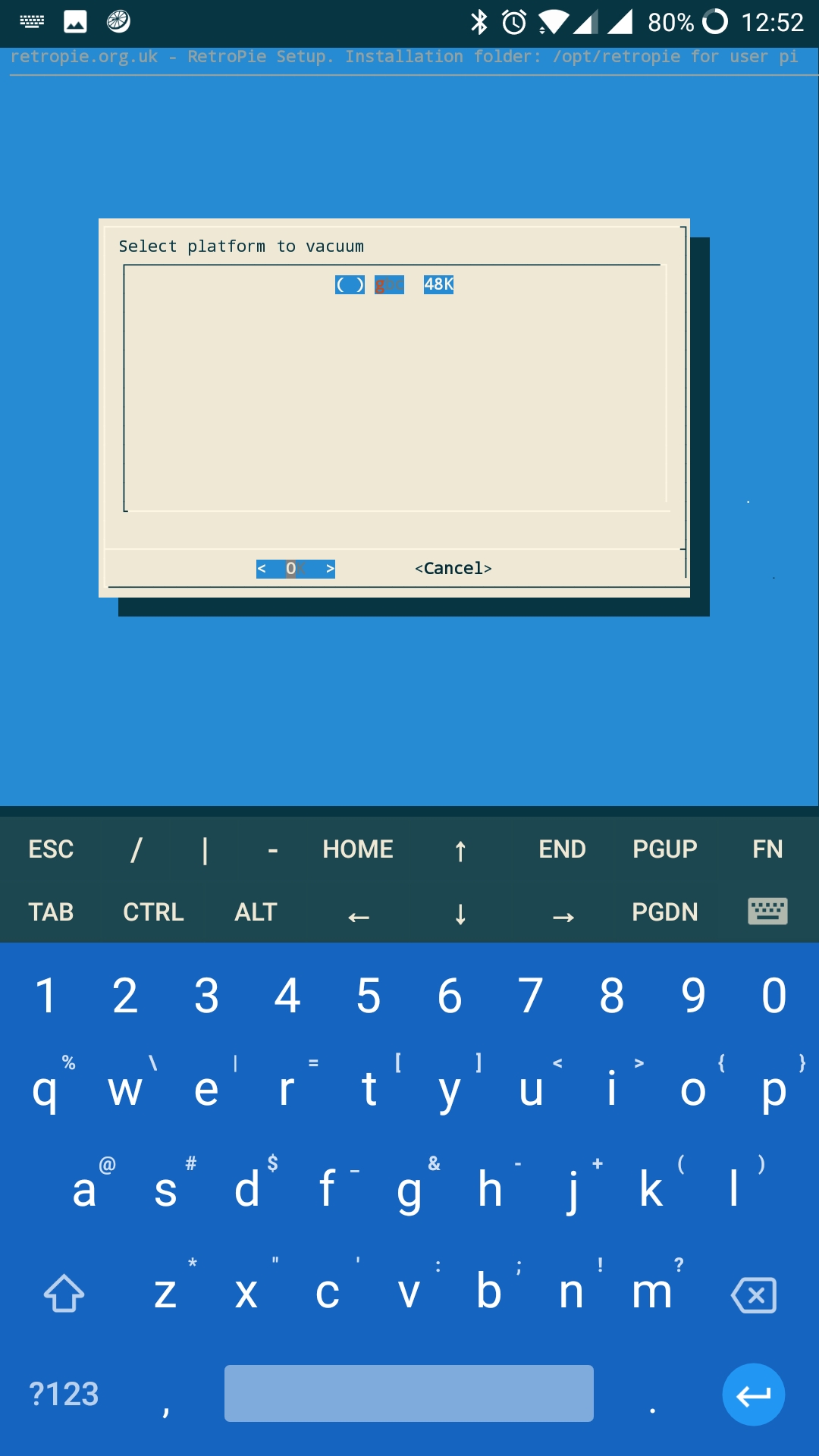
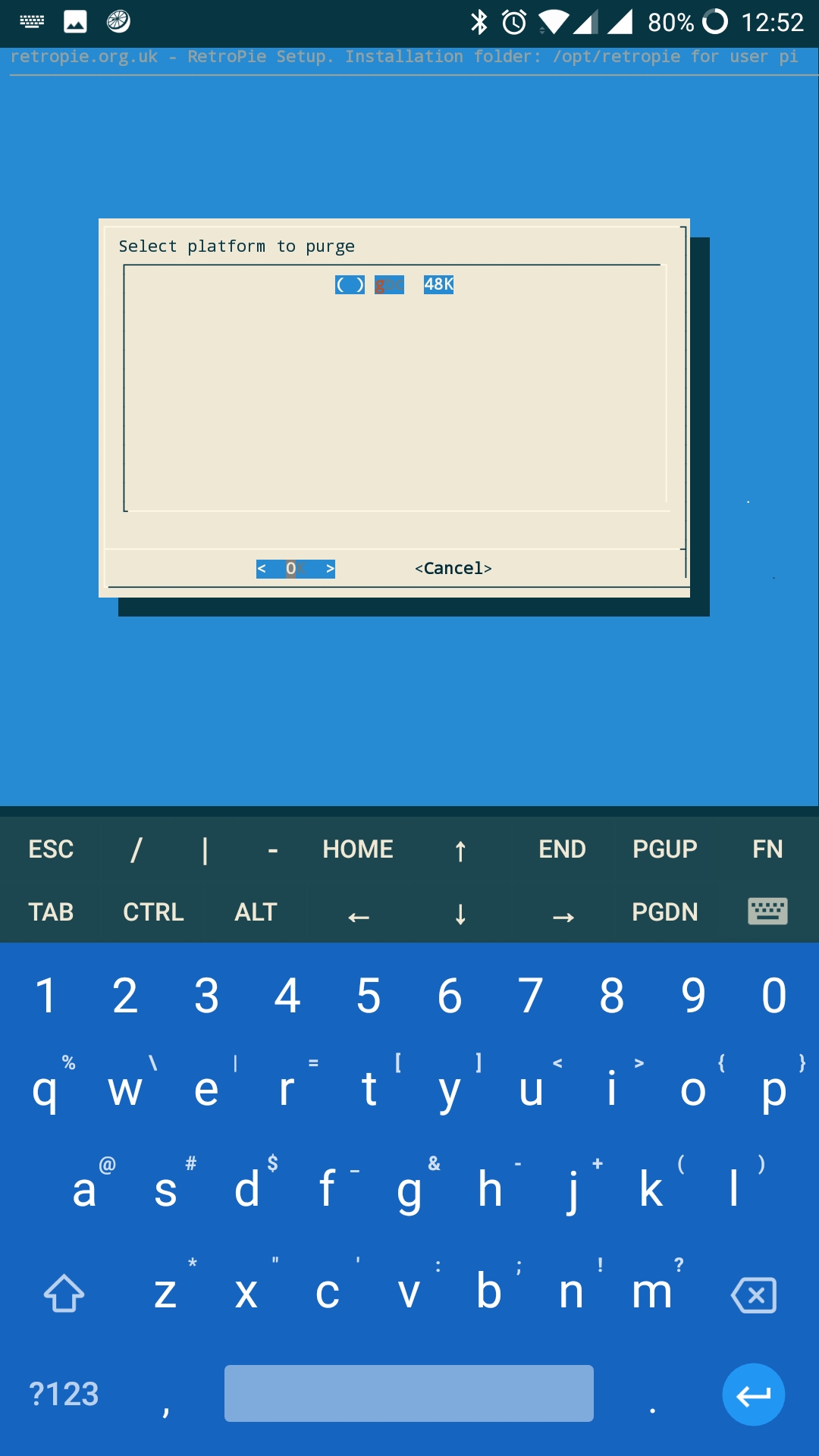
(Excuse the keyboard, sorry)
-
@2fst4u Man, those are some big pictures. I realised later that the
purge/vacuumactions are only shown in the context of a platform (system) and if you moved the cache before starting scraping, the newly cached platforms will not be available in the selection screen.
You'll have to use the CLI and run the cleanup actions in this case.I might be able to improve the detection of cache folder, but my reasoning is that if a user is knowledgeable enough to edit the
.inifile and move the cache, then they are already familiar with the command line and don't need a GUI.@muldjord is the cache folder a global options, or can it be also set in a platform section in the configuration file ? I might be able to extract the cache location, but if the
.inican contain more than one location (i.e. default location isX, but for platform amiga it'sY, etc.) , then this would not work. -
@mitu unfortunately when I try a manual purge now I get that artwork.xml error I was having earlier. Would that be related to moving the cache too?
Contributions to the project are always appreciated, so if you would like to support us with a donation you can do so here.
Hosting provided by Mythic-Beasts. See the Hosting Information page for more information.